How we built the SQL Shell

At Materialize, we strive to meet customers where they are. While we provide our users with an operational data warehouse that presents as PostgreSQL, getting access to a Postgres client (such as psql) and accompanying credentials can be a challenge for those just getting started or wanting to run a handful of exploratory queries. As the entrypoint into Materialize for many of our users is our web console, we saw the need to bring a psql-like experience to the browser.
There are some nearly magical technologies that allow developers to run a full x86 virtual machine in WebAssembly and render the framebuffer to a canvas. Using that, one can actually embed real psql in a browser. An earlier skunkworks attempt of mine did this very thing. What we quickly discovered is that it didn’t feel right: it was a terminal UI in an otherwise rich application, did not play nicely with the existing authentication method we used within the browser, and required a WebSockets proxy for TCP networking. On top of that, we’d be shipping a whole virtual machine’s worth of bytes to users, which is not a respectful thing to do.
We went back to the drawing board to experiment with different technologies. After a few iterations of experimentation, we landed upon something that felt right: the SQL Shell.
How the Shell Works
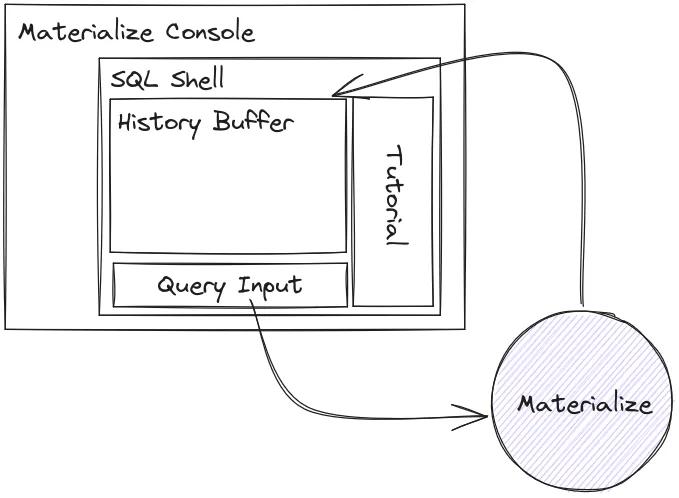
The Shell is a React component in our web application, Console. At a high level it accepts users' SQL queries, sends them to the database, receives a response, and displays the results. On the face of it, it is, but behind the scenes you'll see there is a great deal of depth and capability. Let's see why!
The SQL Editor
Materialize is just like the data warehouse that you already know how to use. We don’t have a custom query language, it’s just SQL! Given our users are entering with a degree of SQL familiarity, we wanted to give them an editing experience that felt familiar. Table stakes here include: syntax highlighting, access to past commands, and familiar navigation shortcuts. Rolling a rich editor oneself is entirely possible, but there’s a long tail of challenges with regards to cross-browser compatibility, accessibility, and support. Thankfully, there exist quite a few editor libraries that satisfy varying needs. We selected CodeMirror as it provided a great core editing experience with support for extensibility, as well as a large community of users. Once we included it in our application, we augmented the first-party SQL syntax highlighting plugin with a collection of Materialize-specific keywords. Additionally, we were able to lean on its extensibility to detect when users are trying to scrub back and forward through their session query history, just like they can do with psql!
Rendering results
If you submit a query, you probably want to see the result of the operation. Materialize will gladly hand you back a collection of table rows, but naively throwing them into an HTML <table> is a recipe for future disaster. Here are some of the concerns that needed to be addressed.
Streaming
Unlike traditional data warehouses, Materialize is built on streaming internals. Where others operate on batches, we incrementally update views as fresh data arrives. A wonderful benefit of these incremental updates is that we can expose this changefeed to SQL clients via the SUBSCRIBE command, which pushes diffs to consumers as they’re computed. The Shell needed to be able to support this non-traditional query/response lifecycle and render data as it comes in. Since this doesn’t play nicely with the traditional HTTP request/response model, we had to look beyond our existing HTTP API and introduced a WebSocket API to Materialize (more on that later).
With that out of the way, we had to figure out how best to handle the lifecycle of the query from issuance to results start, and then to query conclusion. Since we had a discrete set of states and certain criteria dictating when we could exit a state, we reached for a state machine (XState FSM, in this case). By capturing this logic in a state machine, we can push each incoming message to it and easily be able to track the result collections as they grow, as well as accurately determine when queries complete.
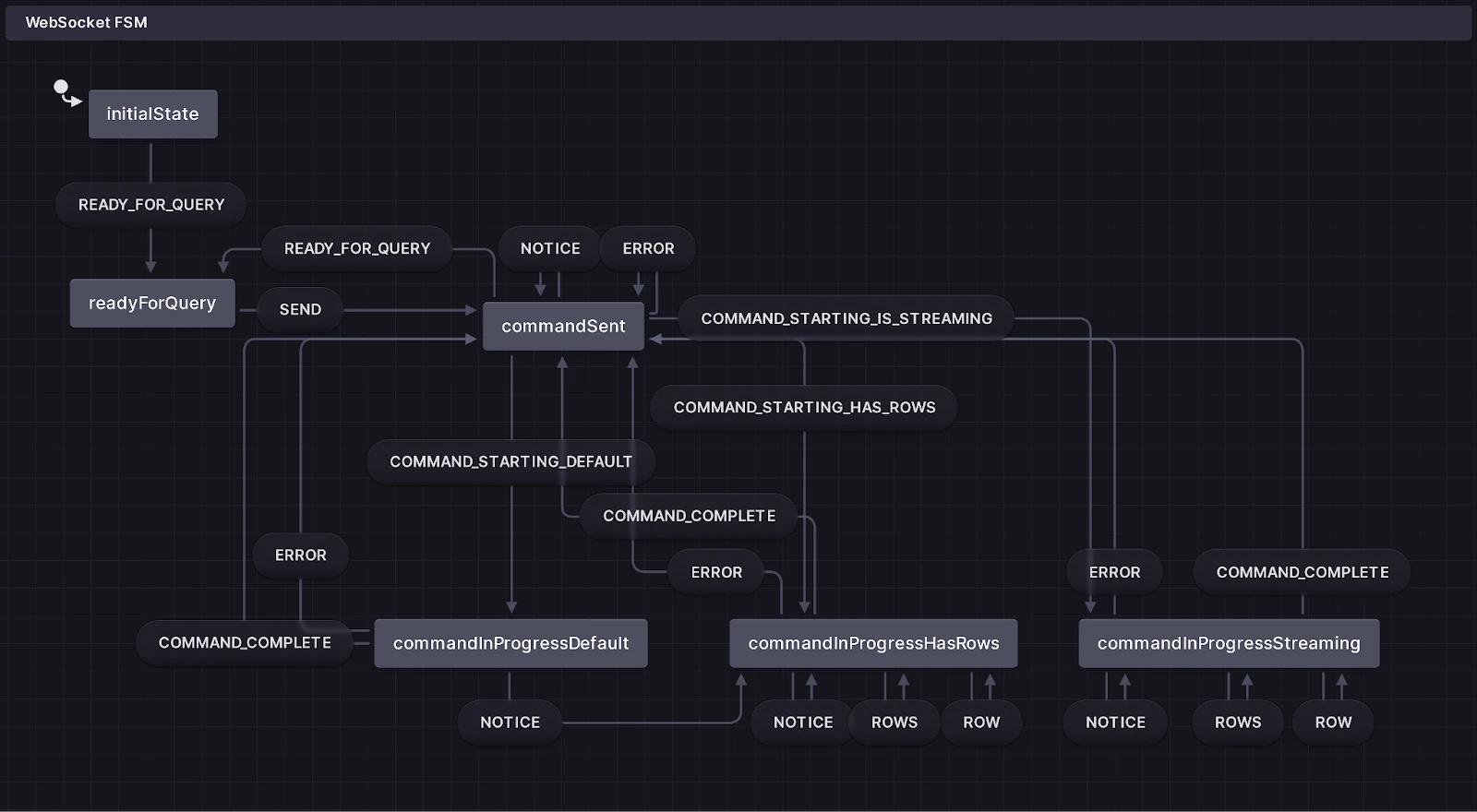
Performance
As results are streamed into the state machine we could immediately sync the computed result set to some component-local variable which would then render the table. However, for sufficiently large results, this can cause performance issues. We addressed this by:
- Using Recoil to manage Shell state. By decomposing state into a series of atoms with derived selectors we can bind components to only the slices of data they care about, reducing renders.
- Treating the state machine as a buffer on our response listener. As results stream in, we use a debouncer to periodically sync the state machine's state to our result atom. This lets us avoid unnecessary intermediate updates as a set of rows arrive from the database.
Presentation
The results view had to be designed with the full spectrum of queries in mind. Some questions we asked ourselves during this process included: "What's a 'reasonable' amount of information to show on the screen?", "How should column values be aligned?" and "How much whitespace should the table have?" To ensure those were kept in mind, we assembled a set of representative queries and used them throughout the design process.
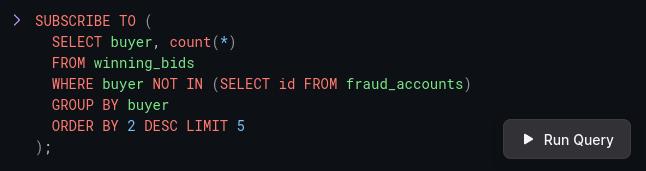
One thing we quickly realized is that, while useful to machines, the raw SUBSCRIBE changefeed may be of limited utility to carbon-based life forms:
To address this, we opted to reduce the diffs into an easier-to-grok table that updates in place as the underlying data changes.
Don't worry about losing the raw diff view, though! As lovers of the web we appreciate the power of "View Source." So we added a toggle to let you switch between the two views (made dead-simple through our Recoil integration).
Ergonomics
Materialize has the concept of a cluster. Clusters allow our customers to isolate compute workloads as well as add fault tolerance to their regions. One thing we pride ourselves on is that everything is just SQL. Where other systems require clickops or special administrative APIs, we allow for full management of resources, inclusive of clusters, through a SQL connection. Users can CREATE CLUSTER <name> SIZE '<size>' and switch to it via SET <cluster>, all from their SQL client.
One piece of feedback we heard from users is they would love to know which cluster they’re working within at all times. For clients such as psql we cannot control the presentation. We can control it within the Shell, however! In fact, we can do it one better. Rather than merely adding the active cluster name to the session, we added a persistent dropdown to allow users to switch the active cluster, too.
To support this we needed some way to react in real time to clusters being created, deleted, and switched. We already have a mechanism for the creation and deletion cases: SUBSCRIBE! This powerful Materialize primitive enables us to opt-in to having catalog updates pushed to clients over WebSockets. Now that we have a continually updated list, how do we determine the current session’s active cluster? Recall that our WebSockets implementation follows the pgwire protocol flow. The protocol provides a way for the database to inform the frontend about the initial state of, or changes to, parameters through a ParameterStatus message. We already emitted messages for a subset of session variables, so it was a matter of adding the cluster to the notice collection, and plumbing ParameterStatus support through to the WebSockets controller. On the Console side we added ParameterStatus support to our WS handler and tracked the variables in session state. Now, when a user runs SET cluster = 'ingest'; the dropdown will update to reflect the change.
Implementing support for changing the cluster from the dropdown was relatively straightforward. As mentioned earlier, we wanted to drive home the fact that "it’s just SQL". To that end, rather than silently setting the cluster on the WebSocket connection, we opted to echo the corresponding SET cluster command to the user, as if they had inputted it. This had the added benefit of not requiring us to introduce the special-case of a silent command.
Scaling
As one starts accumulating large amounts of data in the browser and putting large numbers of components on-screen, they need to be judicious with what is rendered and displayed. In the early days of Shell development we encountered some pathological cases where it would become sluggish, and sometimes even crash the tab. We put those concerns to the side initially – striving to be correct first. Once the baseline functionality was locked in, we sanded the Shell down. We made it performant by adding (in increasing order of complexity):
- Pagination. Large query result sets can present a suboptimal UX, while also hindering performance by pushing an equally-large number of nodes to the DOM. We opted to paginate large result tables to keep the entire table within our target viewport sizes (enabling easier analysis). This also capped the number of DOM nodes a single result set could have. We added support to the WebSocket API to allow us to set a maximum response size, too, to save users from totally crashing their tabs.
- Memoization. We identified expensive parts of our render loop that didn't need to be recomputed each time and wrapped them within
useMemo()to ensure they weren't unnecessarily recalculated. - Virtual scrolling. Your browser will render all parts of a page, even those that are offscreen. For most documents this is fine, but for data-intensive applications this can drag down performance. A commonly used solution here is virtual scrolling, where only content that should be in-viewport is rendered to the DOM. As the user scrolls, the application detects what should be scrolling into the viewport and adds it (while hiding what has just scrolled off). With a little elbow grease we added react-window to the results view and drastically reduced the number of nodes in the DOM.
The WebSocket API
As mentioned earlier, our existing HTTP API didn’t meet the needs of the Shell, so we had to look beyond. Since Materialize is wire-compatible with PostgreSQL, could we just speak its protocol (pgwire) directly from the browser? Unfortunately not. Even if we had the appropriate codecs available, browsers intentionally limit what protocols you can use. So, to achieve the ergonomics we wanted within the realm of available browser technologies, we looked to WebSockets.
Materialize didn’t support WebSockets, however. There exist WebSockets proxies that accept arbitrary TCP packets and, switch-like, distribute them to upstream services. We could tunnel pgwire over such a channel, but there are two challenges with that method:
- We'd have another piece of infrastructure to maintain, and
- Each client would need to explicitly generate a unique application password to authenticate with the upstream database.
While neither was a showstopper, they wouldn’t necessarily provide the characteristics we’re looking for in a solution. Digging further, we had a thought: Materialize already supports authenticated HTTP communication (via both basic and JWT auth) with its /api/sql endpoint, and speaks pgwire over its TCP endpoint. What if we put a thin WebSockets layer over its pgwire handler?
So that's what we did.
With some refactoring to generalize our pgwire handler, we were able to expose a WebSockets endpoint that accepted both simple and extended-syntax queries and returned JSON-serialized versions of pgwire messages. Since this is all built into environmentd (our control plane), we can maintain it as we do the rest of our customers' database infrastructure.
One fun wrinkle we encountered here was around query cancellation. The pgwire protocol states that this needs to happen out of band of the existing connection, so we couldn't just publish a cancel_request message to the already-open WebSockets channel. Closing and reopening the WebSockets channel would achieve the same thing, but we'd lose session-local state, including variables and temporary tables. Instead, we had to plumb support for cancellation through both the frontend and database. Postgres's cancellation flow requires a BackendKeyData message be sent to the frontend upon initial connection that provides an identifier for the session. Adding support for that was straightforward.
On the other end, however, Materialize didn't yet support the pg_cancel_backend() function. Since it is side-effecting, it carries no small amount of complexity and can really mess with query planning and execution. To accommodate this use case while minimizing future pain we opted to constrain the sorts of queries in which this class of function could be invoked. Once shipped, it was a matter of having the Shell issue a traditional HTTP API request that ran SELECT pg_cancel_backend(<BackendKeyData value>).
Quickstart Tutorial
At this point we had a perfectly cromulent Shell, but recall that some of our users may not be all too familiar with the unique functionality that Materialize brings to the table. Dropping them into a blinking terminal without any guidance would be confusing. Traditionally, we had referred folks to our quickstart tutorial, but asking someone to juggle tabs or windows is suboptimal. Since we own both the application and the docs, we decided to embed the quickstart tutorial as sidebar content that can be dismissed if you already know what you're doing. From here, users were able to follow along by copying and pasting the sample commands into the Shell.
Why stop there, though? One huge benefit of the Shell is that it's just HTML, CSS and JavaScript. These technologies are designed to work together. Rather than requiring our users to copy and paste code to execute, why not let them just run it? Very few lines of code later, they could.
Now users can follow along without transcription errors or needing to deal with text selection challenges.
Wrapping Up
Developing and launching the Shell was a cross-cutting effort at Materialize, engaging folks from multiple teams. It's been wonderful to see our customers pick this up and integrate it into their workflows. The feedback we received has been positive, with requests for additional functionality. Keep your eyes peeled for future feature drops!
