A guided tour through Materialize's product principles
September 22, 2023

Materialize is an Operational Data Warehouse: a platform where you land operational data and implement operational behavior in SQL. To achieve this, Materialize needs to provide behavior that goes beyond what existing tools offer. One way to understand its capabilities is through Materialize's product principles: inviolable rules that we view as the sources of value in Materialize. This post kicks off a series where we introduce and then dive into Materialize's product principles. Over several posts we will unpack what Materialize needs to do well, how Materialize aims to achieve them, and how to see each happening (or not) in the platforms you might consider.
Materialize has three core pillars of product value: reasons you might benefit from Materialize, and things we need to not screw up for Materialize to make sense to you and folks like you.
- Trust captures your confidence moving operational work to Materialize. When you ask Materialize to do something you should trust that we will do so as well as your most reliable human operator (but a fair bit faster).
- Scale captures your ability to get as much (or as little) Materialize as you and your organization need. We don't want you to outgrow Materialize just because you find it useful and want (or need) more of it.
- Ease captures your effort invested in starting out, maintaining, and expanding your use of Materialize. The less time you spend worrying about your tools the more you can do with those tools, and we both want that.
To get in front of any cynicism, these values are absolutely as much in our interests as they are in your interests. We want Materialize to be valuable, but our best strategy to date is to build a product that provides manifold value to you, your organization, and all the organizations like yours.
Trust
<YoutubeEmbed data={{ embedId: "z5FW6IEXlQ8" }}/>
Trust unfolds into three characteristics we found at least partially missing from most offerings:
- Responsiveness: Do you get responses to queries and commands promptly, or do you need to architect around non-interactive access?
- Freshness: Are input data promptly moved through operational logic, maintained for applications, and communicated onwards, or do you need to reduce the cadence of your work to match the system?
- Consistency: Does the system present as an interleaved sequence of commands and data updates, or do you have to learn about "anomalies" and figure out what actually happened?
You can sacrifice any one property, and you get an existing class of solution:
- If freshness and consistency are paramount but you can take some time to set up new work, then you might be interested in a stream processor.
- If responsiveness and consistency matter but you can tolerate stale data, then a conventional analytical data warehouse may be good enough.
- If responsiveness and freshness are critical but you can fix consistency issues in application logic, caches and bespoke microservices may get the job done.
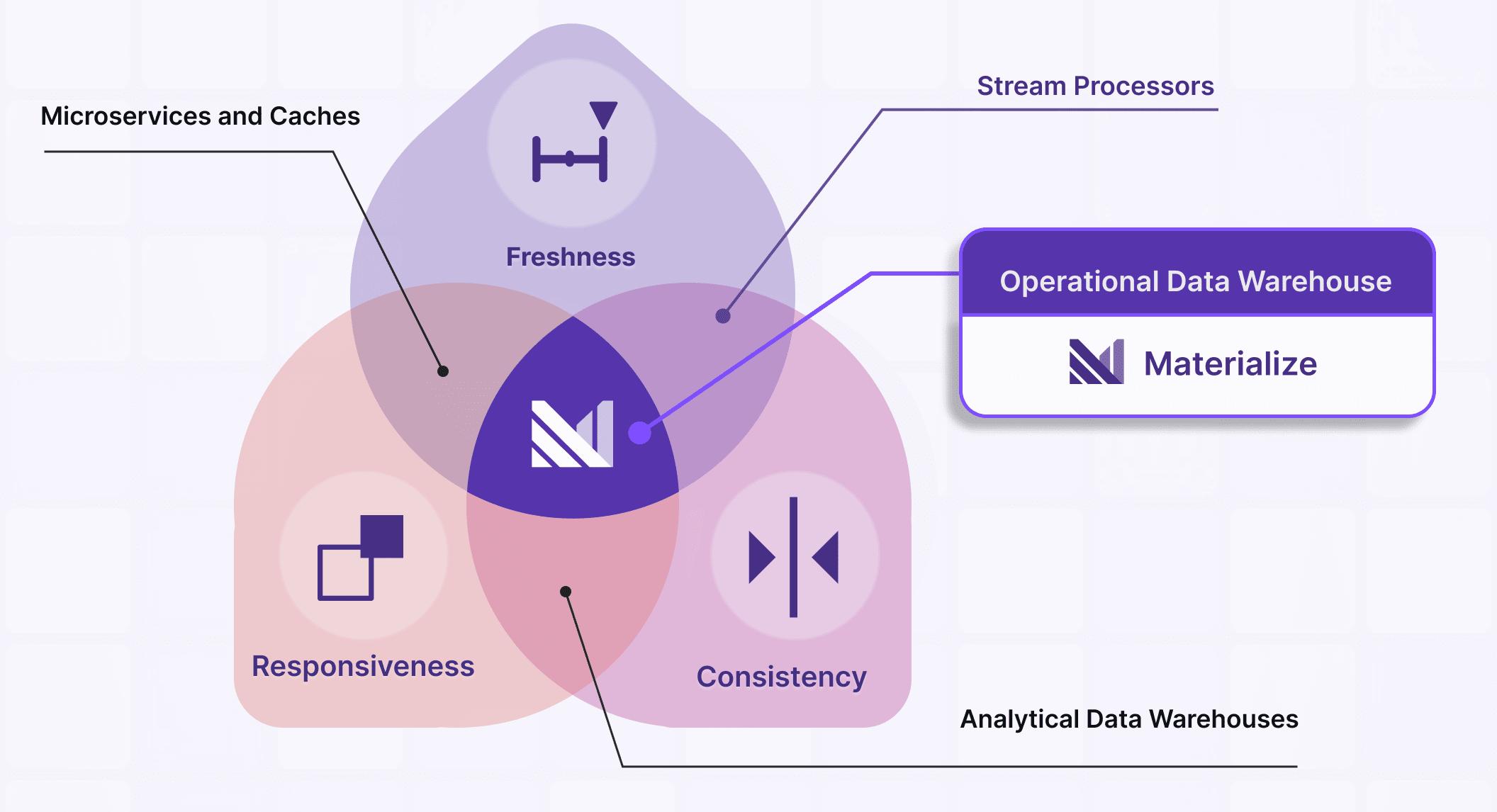
Do you need to sacrifice one of the three properties? Well, yes and no. There are workloads that fundamentally can't provide all three at the same time, at least not without some caveats. However, one can build a system that can do all three (we did) and you shouldn't have to choose one property to permanently sacrifice. For many workloads, you can have all three properties at the same time.
The three properties lead almost directly to three things Materialize must do. To be responsive we must maintain result data in indexes. To be fresh we must do work proactively, which means dataflows. To be consistent we must have concurrency control (we use virtual time). If you don't have access to analogous tools in your platform, it's worth a think to figure out whether you might be missing one of the three properties.
Scale
<YoutubeEmbed data={{ embedId: "t9Ln-v2Avls" }}/>
Scale doesn't unpack as neatly into three component properties, but there are three facets that I think about, at least one of which I find very subtle. These three connect up to the "myriad Vs of Big Data", worth a quick web search to see variegated takes if you don't yet have one of your own.
The volume of data you work with imposes some baseline capacity requirements on your system. As you increase the volume, the data may outgrow a single computer and its venerable hard drive. Modern cloud data warehouses use cloud-native storage to supply essentially limitless storage that grows with you. Materialize also maintains result data (ideally smaller than input data) indexed, and it uses a scale-out compute plane to support growth here.
The velocity of your data speaks to how rapidly it changes. Materialize's computational layer is built around a scale-out dataflow engine that can absorb increasing numbers of updates, with no requirements on the frequency of those updates. We use milliseconds as the quantum of change at the moment, but there's no reason we couldn't get more fine grained.
The value of your use cases is the one that I think is subtle. Additional use cases provide additional value to you and your organization. You'll want to add use cases without negatively impacting existing use cases. Materialize provides several mechanisms for performance and fault isolation, so that you can reliably increase your use of Materialize.
There are certainly other dimensions to scalability, but these three are top of mind for us.
Ease
<YoutubeEmbed data={{ embedId: "ZLlVNMQlxIc" }}/>
Much of the value that Materialize provides is its ability to stand in for expertise you would otherwise need. Materialize does unsurprising things for you using a language you understand. Materialize interoperates naturally with your existing tools and workflows. Materialize clearly explains what it is doing and why, and to what ends. You may be able to figure all of these details out on your own, but that should be your choice.
Of the three pillars, ease is certainly the one that is the most directional and aspirational. It isn't something that can be completely spelled out in just a few sentences or with a cunning diagram. However, it is something that we all know when we see it, or feel it, and we all understand its value. Materialize isn't here to win knock-down drag-out performance slugfests, or awards for fascinating designs. Our goal is to find the shortest path from you and your data to a running operational workload.
Together: A platform for operationalizing your data
Materialize is of course more than the sum of its parts, but these three pillars of product value speak to what we view as most important for an operational data warehouse. You should be able to trust Materialize to act on your behalf for operational work. You should expect Materialize to scale as you introduce more operational work. You should find operational work as easy as you currently find analytical work. We believe that if we cleave to these principles we'll build something truly valuable for operational work. Of course, we invite you to try Materialize yourself! Our guided tutorial is designed to demonstrate each facet of the trust principle through worked examples, and some amount of ease at the same time. To exercise scale you should reach out to us about doing a Proof of Concept!
