Testing Materialize: Our QA Process
May 13, 2024

I joined Materialize’s Quality Assurance (QA) development team over a year ago. Since our team is small, we have to be conscious about focusing our time on the most impactful testing and test tooling.
Our goal is to find issues in Materialize as early and as efficiently as possible, ideally before a pull request even lands. Despite our small team, Materialize has a huge surface area:
- Applications interact with Materialize using the Postgres protocol
- Users additionally run queries using HTTP and WebSockets
- Materialize itself is a distributed system with multiple clusters on separate nodes
- Materialize communicates with CockroachDB and S3 services for its internal catalog and storage needs
- Data is continuously ingested from a Kafka broker (plus a schema registry), Postgres, MySQL and Webhooks
- Data is continuously written to a Kafka broker and exported to S3
We support many of Postgres’ features. Materialize also has a complex compute engine based on Timely/Differential Dataflow for incremental results. As with any software, the interplay of all these different components can create friction.
While the end result of Materialize is a simple user experience, all of these internals require stringent testing and other QA measures to avoid regressions. Above all else, we want to keep our customers and developers happy. The following blog will show you how we do this, with an overview of the QA process at Materialize.
QA Team at Materialize
Materialize has a dedicated QA team, currently consisting of two members. Additionally, developers at Materialize are encouraged to write their own tests for the features that they work on. This adds another layer of quality assurance to our process. The QA team focuses on these topics:
- Monitor important features and develop additional tests for them (Plannable)
- Create new testing frameworks and tooling to improve our QA approaches (Plannable)
- Ensure the quality of high risk pull requests: testing, code coverage, nightly runs (Ad-Hoc)
- Maintain green CI/CD pipelines: report issues that pop up, disable flaky tests, improve turnaround times (Ad-Hoc)
- Integrate learnings from incidents and near-incidents into our testing to prevent similar issues in the future (Ad-Hoc)
By tackling these priorities, the QA team makes sure we put the best software into the hands of our users.
Development Practices
Before we start with our testing approaches, let’s look at some development practices that help us maintain the quality of the product.
Rust Programming Language
Materialize is written in Rust, because the Timely Dataflow (TDF) and Differential Dataflow (DDF) libraries that it uses were written in Rust. Our co-founder Frank McSherry built TDF and DDF at Microsoft Research, years before Materialize started.
Rust’s memory safety makes it harder to randomly overwrite memory and induce a segmentation fault. It’s of course still possible, but requires one of these:
- C/C++ libraries we depend on (example)
- Unsafe Rust code in our code base or a library we depend on (example)
- A Rust compiler bug (example, although this only crashed during compilation, so not as bad)
See the Sanitizers section for how we deal with these situations.
Compiler Warnings and Lints
The Rust compiler as well as linters like clippy offer many useful warnings, which we enable and enforce in CI in order to merge PRs. Setting enforced code formatting using rustfmt and pyfmt removes distractions during code reviews. This enables the reviewers to actually focus on what’s important about the change instead of styling.
Deterministic Tests
In general, the QA team writes tests using the least powerful tool that covers the feature in question. This makes debugging regressions easier.
At the same time, the QA team wants to test functionality in the scope of the full system to make sure it interacts well with other features.
Unit Tests
Developers are encouraged to write their own unit tests to assess parts of the code in relative isolation. Here’s a sample unit test:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | |
21 | |
22 | |
23 | |
Unit tests are an area the QA team is rarely involved in, since our approach is to consider all of Materialize as one system. Our goal is to ensure that the system interacts well as a combination of units. Miri is a Rust interpreter that can run a subset of our unit tests and detect undefined behavior. The rest of this blog will describe tests utilizing a more full-fledged Materialize instance.
Sqllogictest is a test harness that originates in SQLite. Each file is run in isolation and contains queries with their expected outputs, whether they are successful return values or errors:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
We use extensions that CockroachDB defined, as well as SLT test files from SQLite. SLT is limited to queries running against Materialize using the Postgres protocol.
SLT can’t interact with external systems like a Kafka/Postgres/MySQL source to ingest data. It also can’t interact with a Kafka sink or S3 to verify exported data.
Testdrive
This is where Testdrive comes in. We invented Testdrive specifically for Materialize, so it is perfectly suited for the features we support.
For example we can use Testdrive to write data into a Kafka topic that is connected to Materialize as a SOURCE, verify the data in Materialize, and check that the resulting data is correctly written to a Kafka SINK:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
The same applies to ingesting data using MySQL, Postgres, and Webhooks, as well as verifying data in S3.
Mzcompose
For more complex testing we use our own mzcompose framework. This framework is written in Python and wraps and extends Docker Compose. mzcompose allows defining services (each a separate container), how they talk to each other, and then running workflows against them. Here’s an example:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
Mzcompose-based tests often use Testdrive, but we can achieve the same directly from Python as well. We will implement most of the remaining tests in this blog on mzcompose, due to its flexibility.
Platform Checks
The Platform Checks framework allows you to specify checks and scenarios once, and then run them in any combination with each other. A check is an individual test, such as deleting data, as seen below:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | |
21 | |
22 | |
23 | |
24 | |
25 | |
26 | |
We can see that there are three separate phases: initialize, manipulate, and validate, executed in this order. These phases are executed inside of scenarios. The scenarios can upgrade Materialize during each step, like in this example:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | |
21 | |
22 | |
This allows us to run each check in combination with each scenario. That’s a great way of finding bugs during events like restarts and upgrades, when data has to be serialized and deserialized/migrated. Whenever new functionality or syntax is introduced, we must write a platform check for it.
Toxiproxy
While there are many mzcompose-based tests, they are all quite similar to each other. So let’s instead discuss Toxiproxy, a TCP proxy that can simulate various kinds of network problems. We use Toxiproxy to verify that Materialize recovers properly from connection problems to its Postgres, MySQL or Kafka sources.
Testdrive even supports sending the required HTTP requests directly, in this case breaking the connection to our Postgres source and afterwards verifying that Materialize is correctly noticing the connection error:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
Randomized Tests
Deterministic tests are easy to understand and debug. But they will only cover what was explicitly considered by the test. There is often considerable overlap between the assumptions of production and test code. Even when the test and feature developers act separately, some overlap remains.
Randomized testing is able to cover such cases, along with edge cases and implausible combinations of features. We use a fixed seed and print the used seed for each run with randomized testing. Otherwise reproducibility of rare bugs suffers.
Output Consistency
The output consistency test framework creates queries using many of our supported types, functions, and operators. Then the result is compared against a reference. This reference can be an older version of Materialize that catches regressions.
Usually this should be intentional differences, for example when a bug is fixed. But it also catches unintentionally changed results, even without having ever written a specific test for the functionality. For example, in Materialize v0.93.0 the result for this query changed compared to v0.92.1:
1 | |
2 | |
3 | |
Before:
1 | |
2 | |
3 | |
4 | |
After:
1 | |
2 | |
3 | |
4 | |
5 | |
We use a similar approach to compare Materialize against Postgres. This enables us to map edge case differences in functions in comparison to Postgres.
SQLsmith
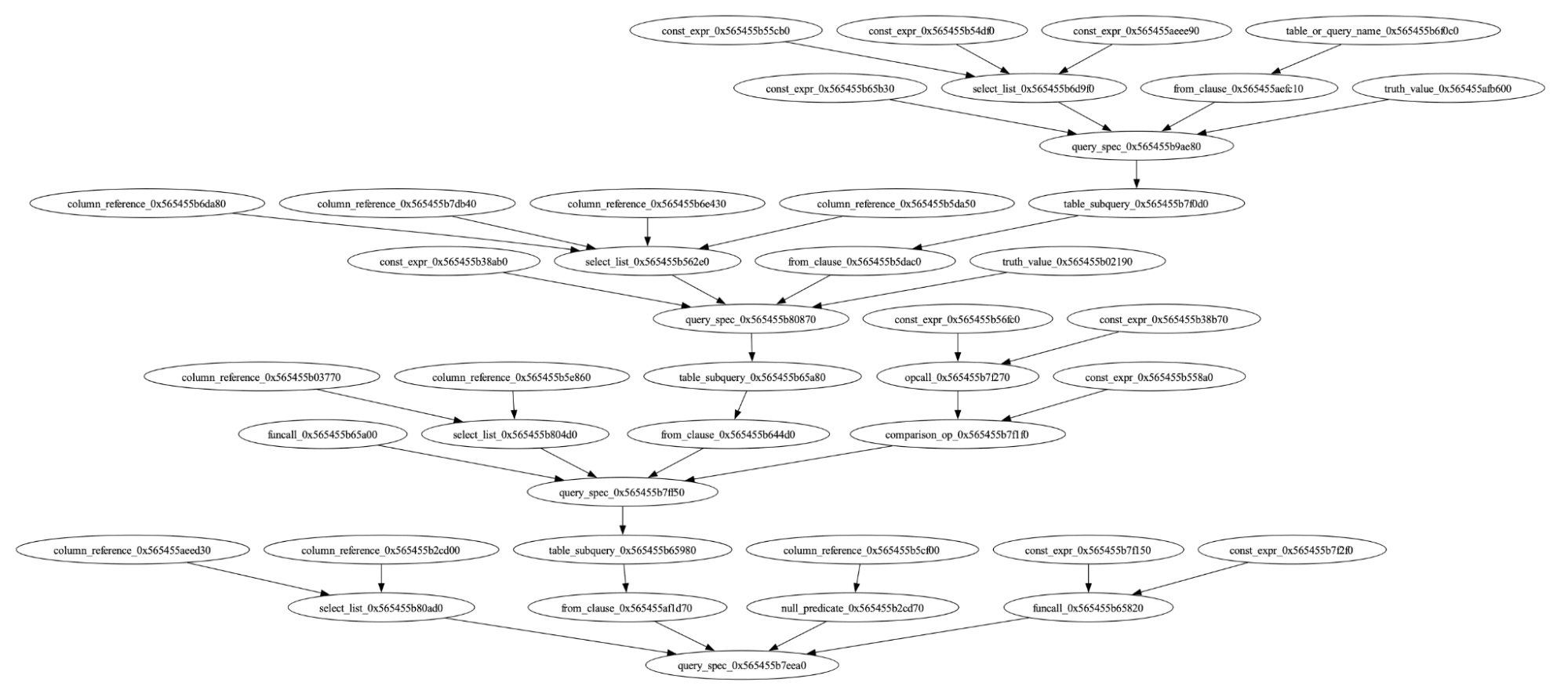
For a tool like the Output Consistency test, the queries can’t be too strange. Otherwise, both answers could be correct. SQLsmith is an open source tool that we’ve forked and adapted to Materialize. The tool excels at creating huge queries containing rarely used functionality.
It works by initially scanning the DBMS for the available tables, types, functions, operators via introspection tables and then creates SQL ASTs combining all of those together. It’s not clear what the queries should return, but it’s definitely not internal errors or panics, which is what SQLsmith excels at finding.
SQLancer
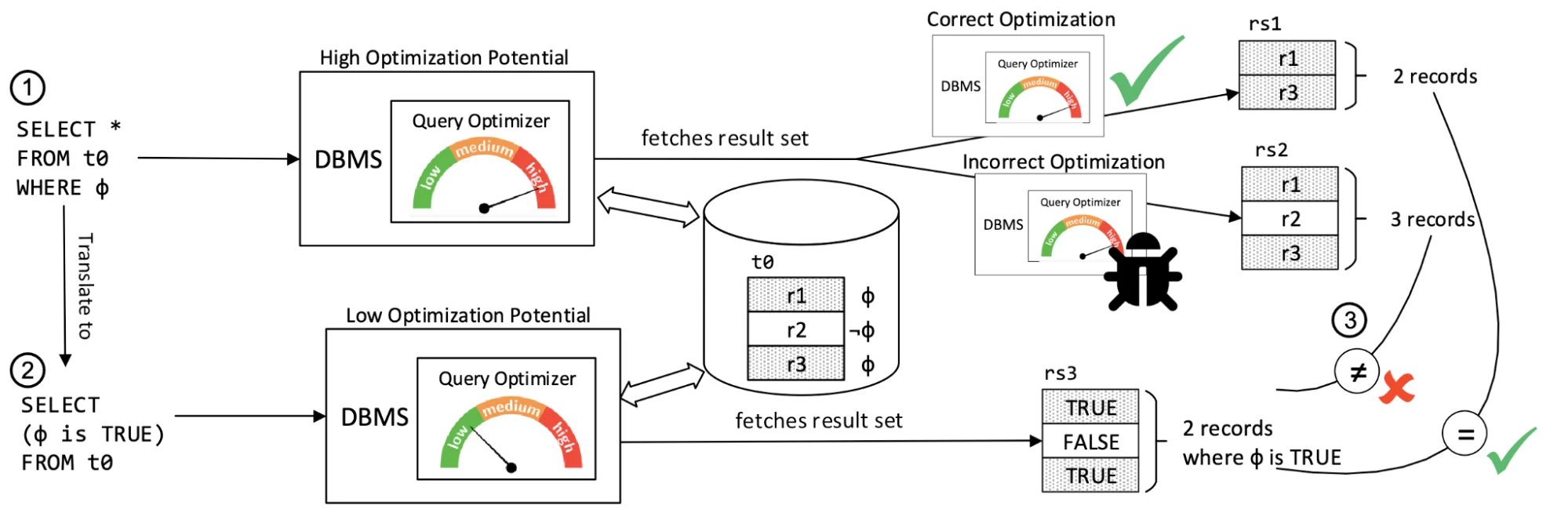
SQLancer is another excellent open source testing tool that we’ve ported to Materialize. It has multiple clever approaches for validating the correctness of queries without an oracle — that is, a previous version, or Postgres in Output Consistency.
But since SQLancer and SQLsmith are both generic tools that work for many different DBMSes, they don’t utilize some of the most interesting parts of Materialize, like sources, sinks and materialized views.
Zippy
That’s why we created Zippy, another testing framework invented here at Materialize, and thus custom-built for our purposes.
Zippy creates random Testdrive fragments which ingest data into Materialize, uses materialized views as well as indexes and then, still in Testdrive, validates the expected results based on its internal tracking. By defining actions and scenarios it’s possible to create interesting test cases using Zippy:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | |
12 | |
13 | |
14 | |
15 | |
16 | |
17 | |
18 | |
All of these actions are run single-threaded, which is a blessing for reproducing them, but a curse for finding race conditions.
Parallel Workload
This is where parallel-workload comes in. A parallel workload is composed of:
- Actions: Select, CopyToS3, Fetch, Insert, HttpPost, SourceInsert, Delete, Update, InsertReturning, Comment, various DDL actions
- Complexity Select a subset of actions: Read, DML, DDL, DDLOnly
- Scenario: Regression, Cancel, Kill, Rename, Backup&Restore
- Data Types: Boolean, SmallInt, Int, Long, Float, Double, Text, Bytea, UUID, Jsonb, Map[Text=>Text]
- Objects: Table, (Materialized) View, Index, Kafka Source, Kafka Sink, MySQL Source, Postgres Source, Webhook Source, Cluster, Cluster Replica, Database, Schema
Randomly chosen actions run in parallel on the existing objects, which enables us to run into interesting race conditions. However, this makes reproducing issues and checking correctness more difficult. The parallel-workload framework becomes more useful with better assertions in the production code.
Tooling
Detecting Closed Issues
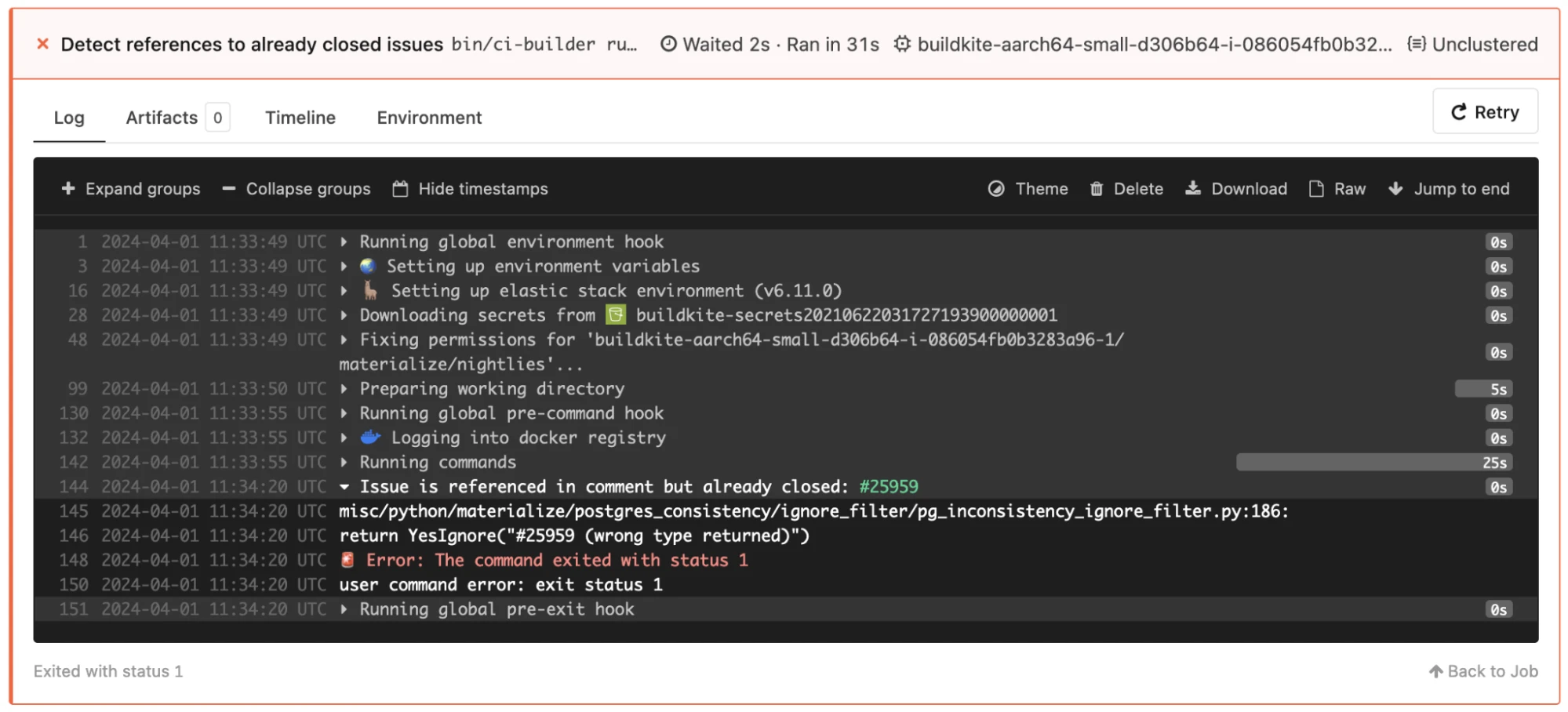
Flaky tests are extremely annoying. The first step should always be to fix the issue. If that can’t happen quickly, we sometimes have to temporarily disable a test.
To make sure we don’t forget to re-enable the test once the original issue is fixed, we check comments for references to closed GitHub issues, and notify QA about that via our Nightly test runs’ ci-closed-issues-detect.
Annotating Errors

When the tests for a flaky issue can’t be easily disabled, for example if it affects many different tests, but occurs very rarely, we annotate errors based on regular expressions in the GitHub issues. This enables us to to detect occurrences of the same issue in the output and logs.
As a bonus point this can also tell us when a bug was already fixed previously, but has since regressed. Showing the main branch history of a test helps developers figure out whether they might have broken the test in their PR.
Continuous Heap Profiling
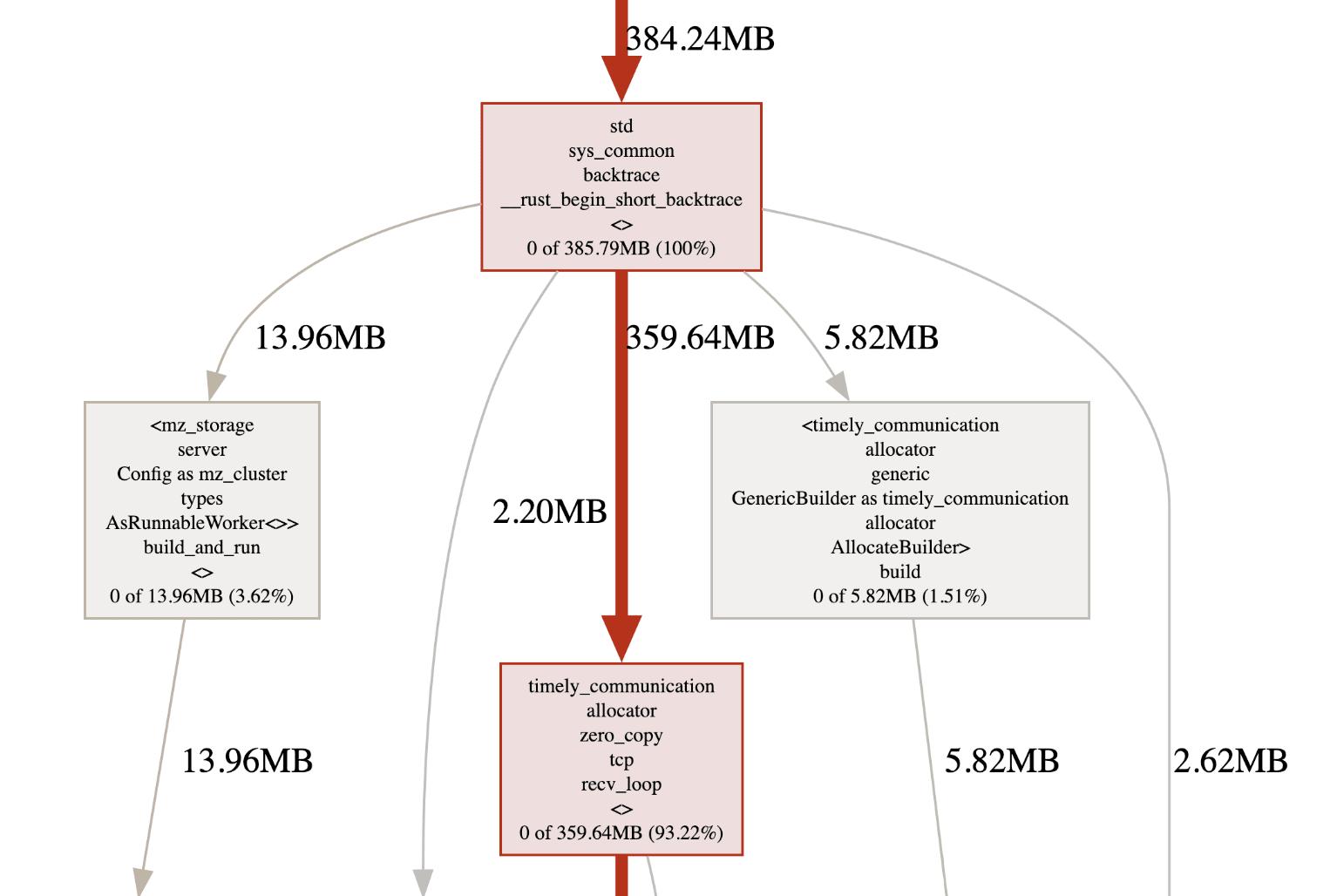
Memory regression is a relatively common occurrence in Materialize. In Materialize, large chunks of data are kept in memory to maintain incremental views. Our allocator jemalloc supports cheaply fetching heap profiles. We expose this in our Materialize executables. These heap profiles can then be symbolized and analyzed after the fact.
We have tools to automatically upload these heap profiles as Buildkite artifacts for later analysis. This makes it easier to figure out which part of the code is actually allocating more memory instead of having to guess or bisect when a memory regression occurs.
Code Coverage for PRs

Introducing full code coverage for a mature project is difficult. Also, code coverage can easily be gamed. See Goodhart’s Law for a more general expression of this phenomenon. Instead, we opted for checking the code coverage of risky pull requests.
Risk is classified by Shepherdly based on previous bugs and what files were affected by them. If we consider the lines changed in a pull request, this will allow us to ask why no test is exercising a specific part of production code, or use this as the starting point for our own testing.
Since this is happening in the scope of reviewing the PR, the code coverage gaps are immediately actionable and related to what the developer is already working on. In general, uncovered code can tell you that tests are missing for a specific block of code, but the existence of covered code does not imply that the test is actually doing anything useful.
At worst, this only ensures that there is a single code path through this block of code which does not crash.
Sanitizers

Materialize contains some unsafe code, links in Rust libraries with further unsafe code, and C/C++ libraries that make it difficult to assess safety. It is possible to enable sanitizers like the Address Sanitizer in all of our code, including the C/C++ libraries, for extended testing. Since this is much slower, and we already have our hands full with regular CI runs, sanitizers are currently reserved for manual runs.
Triggering CI
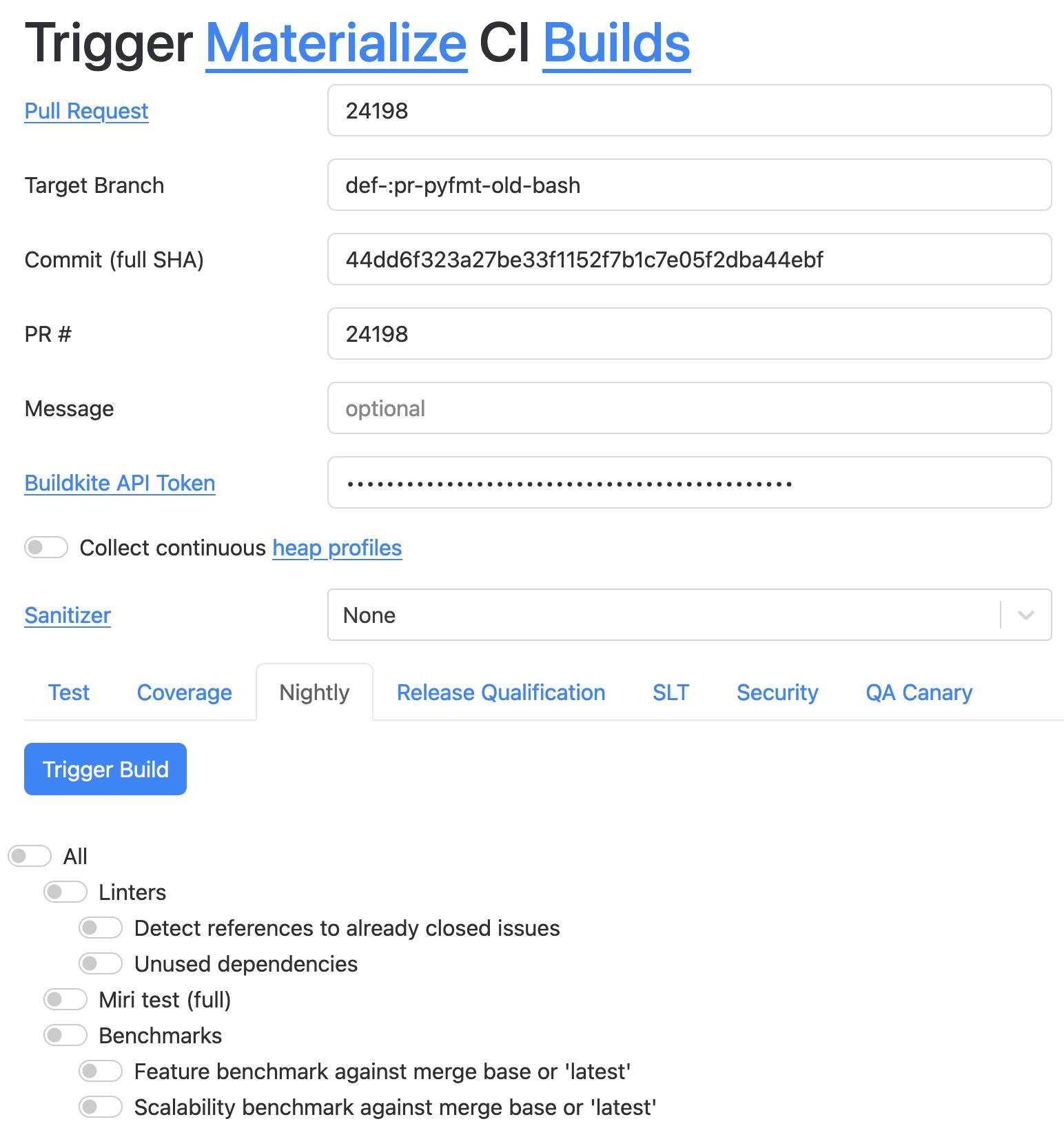
We offer a simple way for developers (and ourselves in QA) to trigger custom test runs in CI with different settings, like continuous heap profiling, sanitizers, code coverage. Enabling everyone at Materialize to use the tooling we have developed in the QA team has proven fruitful in empowering developers, so that in many cases QA does not have to be involved directly but only provides the tooling.
Materialize QA Team - This is Just a Sample
This has only been a sampling of some of the tools and tests that we employ. At Materialize, we’re happy with what we’ve built and automated on the QA team to prevent new issues and regressions. With Materialize’s huge surface area, there’s still much more room for testing and QA tooling to grow more extensive, and we look forward to continuing to expand our capabilities in the future.
