Lower Data Freshness Costs for Teams | Materialize
August 29, 2023

success
Summary: In analytic data warehouses, increased freshness means increased costs as you ramp up your query cadence. In Materialize, you pay a fixed amount to maintain your queries, and they are always up-to-date. As your operational work needs more freshness, you'll want to move it out of your analytic warehouse and into Materialize.
Previously, we discussed how the value of fresh, up-to-date data differs in operational vs analytical work. The image below sums it up:
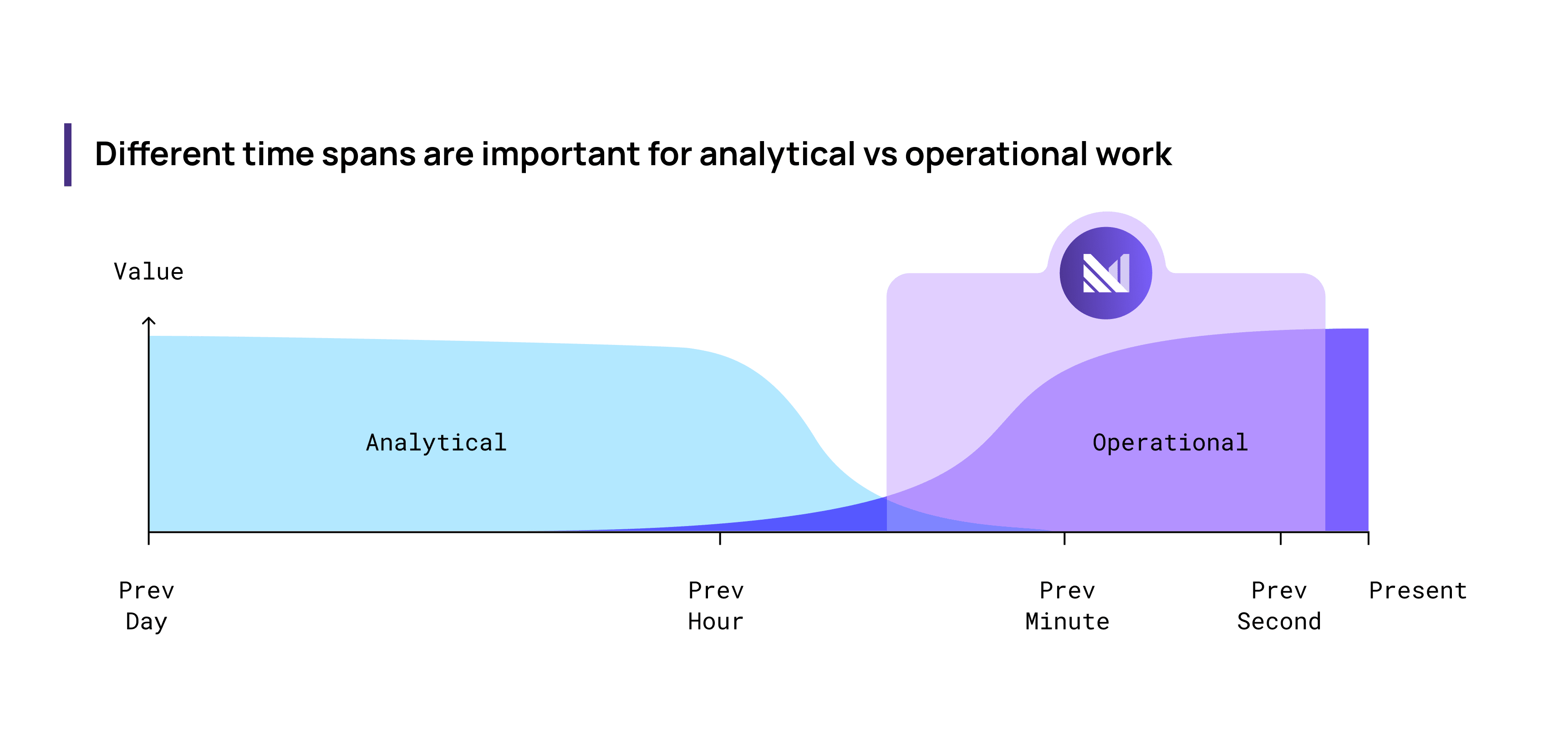
Operational data workloads like personalization, notifications, business automation, ML/AI feature-serving, put more value on up-to-date data. Analytical workloads put more value on historic data. That covers value, but equally important today is cost.
The pay-per-query model lowered costs for analytics
When Snowflake and BigQuery first launched, their ability to offer fungible compute changed the data industry. Most of us only needed their most powerful servers to run a batch transformation job once a day. These new cloud-native warehouses handled allocation of compute behind the scenes and only charged us for the time it took to run the query. The same fungibility in Hadoop meant huge amounts of ops work, and with the earlier generation of data warehouses it was flat-out impossible.
One way to look at: Snowflake and BigQuery delivered a new pricing model that linked cost to data freshness (transformation frequency), and that meant costs were dramatically lower for everyone because analytics workflows really only needed data to update once a day.

But as data teams expand how they use the analytic data warehouse, the cost-frequency link can flip from feature to bug.
But now it's driving up costs for operational workloads
New workloads need fresher data. But increasing transform frequency is sliding the wrong direction up the same curve that made analytic data warehouses so appealing ten years ago.

Materialize decouples cost and freshness
Using the same rubric to look at Materialize, cost is not correlated with freshness because the platform is running computation continuously. Results are updated as soon as data arrives.
For work that benefits from data that is always up-to-date, Materialize is some combination of cost decrease and capability increase, not because we’ve built a better Snowflake but because the model is different and better-suited for operational work. As you can see, this cuts both ways: Running work continuously on Materialize when it only gets used once every 24hrs is going to be more expensive than a daily job on Snowflake.
Other factors like scale of dataset, throughput of changes, and complexity of transformations affect cost on Materialize.
How is this possible?
Incrementally maintained materialized views!
Analytic data warehouses rely on the user to decide the frequency at which a batch transformation query should be recomputed and cached, and default to turning off compute when queries aren’t running. Materialize takes the same SQL and parses it into a dataflow that incrementally maintains the results as the input data changes.
If it runs continuously, how can it ever be cheaper than a model that turns off compute? The key is in the incremental computation.
Imagine you have a complex SQL transformation, and you want the results as up-to-date as possible. In an analytic data warehouse, the same amount of work is required each time it runs. It doesn’t matter if you ran the query ten days ago or ten minutes ago, even if only one row of input data changed, if it took 10 minutes before, it will take 10 minutes now.

Note: For those familiar with dbt, compute efficiency on some repetitive transformations can be gained using incremental materializations, but at a steep engineering complexity cost, as discussed here.
Materialize can handle ad-hoc queries too, but the differentiating features are materialized views and indexes, both of which are computed continuously. Materialize makes it as easy to deploy these "continuous transformation services" as running a query on a data warehouse - the catch, of course, is you are deploying a service and that may not always be appropriate (e.g. if the data is only going to be used once a day).
When you first deploy a materialized view, a batch of computation similar to the scale of that in an analytic data warehouse occurs as the incremental engine churns through the compacted state of data in storage, effectively “catching up to real-time”.

But once caught up, Materialize only does computation work proportionate to the changes. When one row of input data changes in a large transformation, Materialize only does a small amount of work to update the results.
note
Note: Cluster replicas, the Materialize equivalent of virtual warehouses, can be started large and scaled down without disruption to efficiently handle the initial bump in computation.
There are no magic beans in databases. Not every workload is well suited to this new compute model. Teams that find cost-savings bringing workloads from analytic data warehouses to Materialize have workloads with characteristics we cover in detail here.
Conclusion
As your business starts to move beyond just using the analytic data warehouse for serving a business intelligence tool, and delves into using it for more operational-style workloads, think about the freshness requirements of each workload:
- Is there a hard limit? E.g. Dynamic pricing is not possible if end-to-end latency is greater than ten seconds.
- Does the value you can deliver increase as lag decreases? E.g. Every minute you shave off fraud detection latency = $X loss prevented.
Based on the answers, running the work in a tool purpose-built for operational work, a tool that decouples cost and freshness might be a way to deliver more value without erasing all your gains with higher warehouse costs.

