Incremental View Maintenance Replicas: Improve Database Stability and Accelerate Workloads

One of the most important jobs every business has is to keep its databases online. The best way to do this is to never let anyone change them, or query them at all for that matter. Since those aren’t real options, engineering teams have to navigate various trade-offs to hopefully find a balance that lets their business operate and deliver for customers.
One critical trade-off comes down to how data is physically laid out when persisted. The decision has serious performance implications for various workloads. For example, if you know your database is serving massive write volumes, you would organize it differently if it were serving many millions of simple point lookups, or if it were handling complex queries over many rows.
The decision gets more complicated when you try to weigh the monetary costs of these different approaches versus the benefits. To make matters worse, the right balance today may quickly turn into the wrong one as new features are developed or more traffic hits your servers.
Take general-purpose relational databases like Postgres or MySQL. They prioritize efficiency for writing transactions quickly, correctly, and with high throughput. To do this, they give up an architecture that would efficiently support complex queries. This kind of architecture could surface the correctly and durably stored data in a format suitable to clients and end users.
So in practice, what happens when you need to run a complex query against live data to populate a UI? Or run a report for an operational dashboard? Or quickly construct the context necessary to power some business process? Your business doesn’t care that the database wasn’t designed to do these tasks efficiently. The work still needs to happen. The question is: where… and when?
Where the Work is Done
Work can be performed in the database, or somewhere else, with tradeoffs for each option. The best option will depend on your specific requirements and constraints. Here’s an overview of the different methods for performing database workloads.
In the Database
Direct Queries
Every time you need an answer, directly query the database and get a fresh and perfectly consistent result. Views provide a shorthand for more complex queries but still hit the database whenever they are accessed.
Direct queries have the benefit of working with the absolute freshest transactional data, but come with the downside of performance and database impact. The performance degradation happens due to a suboptimal data layout. This also leads to availability issues, since the wrong layout means extra work that takes resources from mission-critical traffic.
Materialized Views
Materialized views allow you to store query results for future use. Instead of recomputing the data every time you need an answer, you run the query periodically, maybe once an hour or once a day, and store the results on disk. Retrieval is fast since you’ve stored the results, but this reduces data freshness. You’re no longer working with the most up-to-date version of data, one of the primary benefits of querying your system of record in the first place.
Finally, while materialized views don’t re-compute your query every time it is executed, the query to populate the view does need to run periodically to update the results. The load to do this – again due to the data layout – can impact foreground traffic and the stability of the database every time the materialized view is refreshed.
Note: MySQL doesn’t natively support materialized views, so these are typically implemented by periodically running a query to create the view, and manually writing the results back to another table, with old results cleared as new ones are written. This creates a similar workload on the primary database to that of native materialized views.
In a Separate Platform
Read Replica
The approach here is to move your complex queries to another instance, or replica, of your database that is listening to changes from the original. This is great for stability, provided you don’t have to fall back to the primary, and also your data is quite fresh. With new engines like AWS Aurora, the replication lag – or time between when data shows up in the primary and is available in the replica – is typically much lower than 100ms.
The main downside is that the replica is still using the same architecture, and data layout, as the primary. This means your complex reads will have high latency and low throughput. Even with this dedicated instance, you might not be able to meet your SLAs. You can scale read replicas up and out, but that isn’t solving the root of the architecture problem, and your cost to serve will skyrocket.
Data Warehouse
Let’s say you decide to process complex queries with a system specifically designed to do this. A popular approach is to create a pipeline that extracts your data from your operational system, loads it into a data warehouse, and then uses the warehouse resources to transform it into a shape that supports very fast querying. The main downside to this approach, beyond the cost, is you lose freshness as now you aren’t working with seconds-old data.You’re dealing with minutes or even hours of lag.
A more general approach here is to replicate to some other system to support complex querying. The name for this pattern is CQRS, and it will generally have its own sets of trade-offs, particularly around complexity, that are outside the scope of this doc.
Summary: Approaches for Running Complex Queries on Operational Data
A Better Approach: Incremental View Maintenance Replicas
Without both fresh data and low latency, running complex queries on live transactions will still occur on a timescale that won’t enable fast reaction times to operational data.
This has been the trade-off for decades. However, incrementally and continually updating materialized views gives us a new path forward.
Incremental view maintenance (IVM) is a technique for updating materialized views as data changes, enabling low latency access to fresh data. Doing this correctly and without pages of caveats has been out of reach for databases for decades.
That’s changed with the invention of Differential Dataflow, which can be deployed using a new pattern that we’ll call the IVM replica or IVMR.
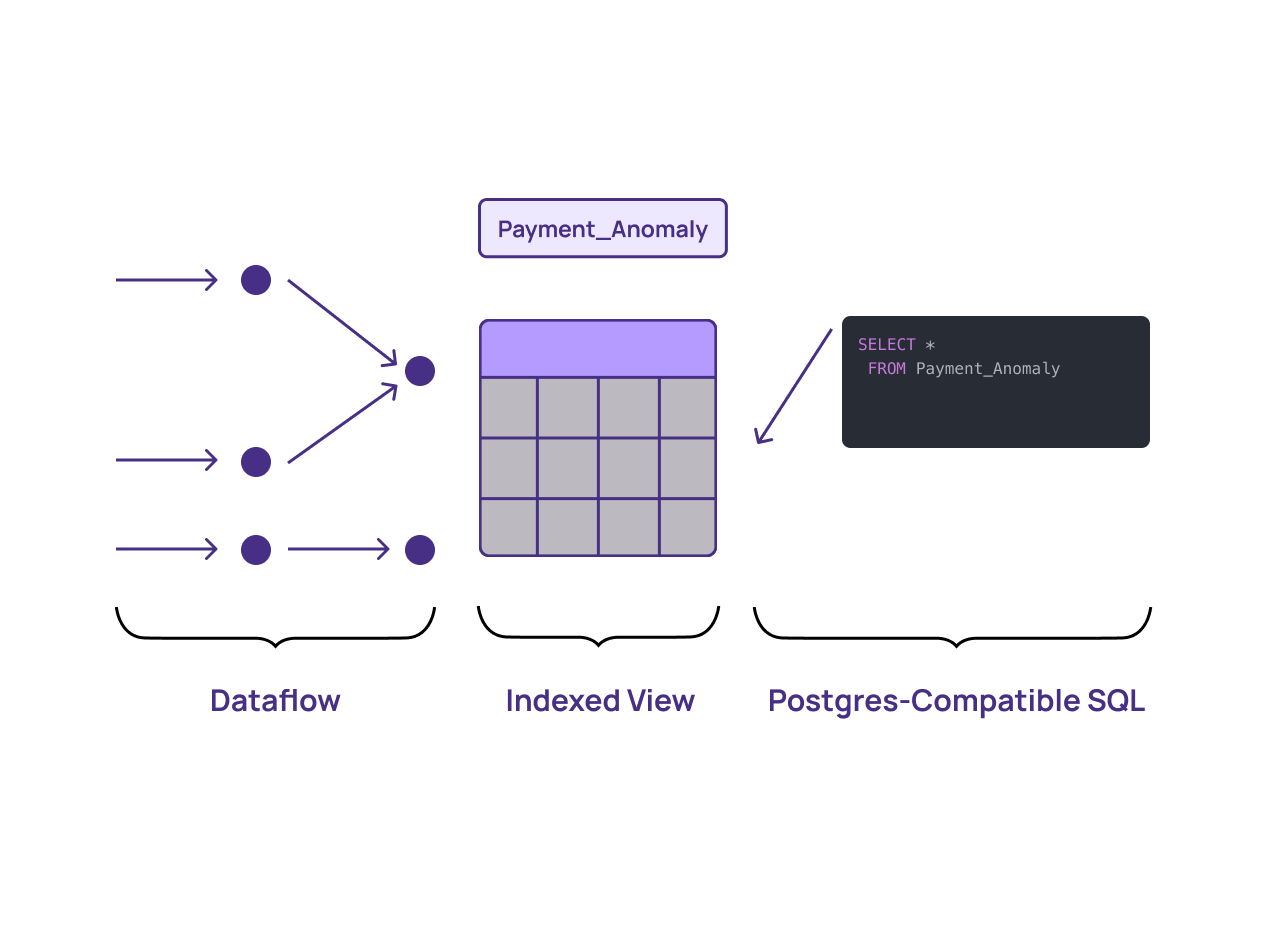
In a SQL database, you can make a table fast by adding an index. With IVMRs, you can add an index on a SQL view. This is extremely powerful because you can now use SQL, with its joins, aggregations, and even recursion capabilities, to create views that are kept up to date incrementally.
IVMRs take the DRY – or don’t-repeat-yourself – approach to the extreme. They can determine, as updates come in, the exact amount of new work that needs to be done to update a materialized view. And then, in an also DRY-like fashion, when you query those views, the heavy computational lifting has already been done and can be reused as a starting point.
This gives you a massive head start on queries, without sacrificing freshness or correctness. The combination of these two approaches enables IVMRs that can deliver 1000x performance for read-heavy workloads, without losing freshness, and do so at a fraction of the price of a traditional replica. IVMRs are less about how the data is shaped and more about when the work is performed.
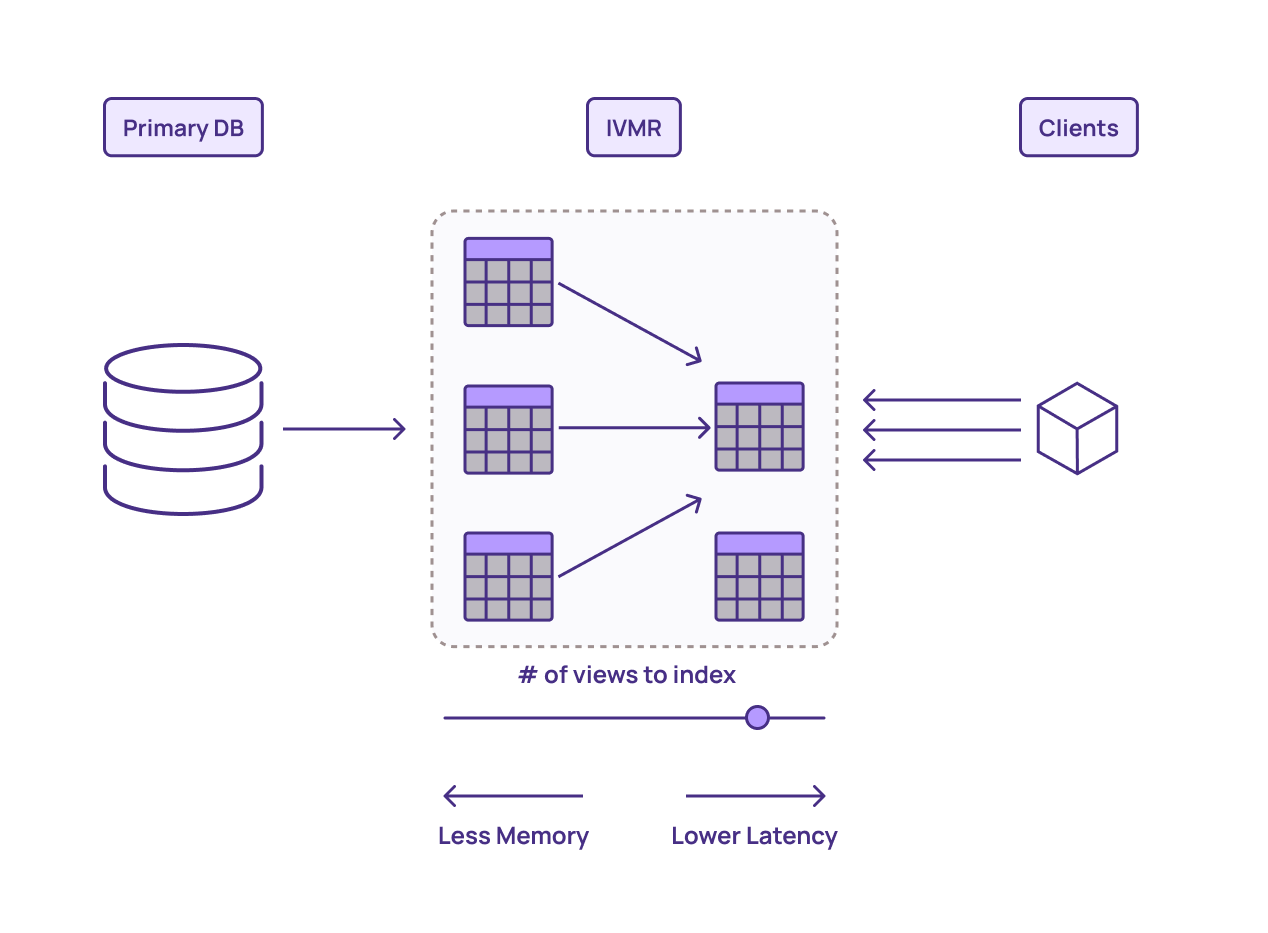
You can think of adding these indexes as a sliding scale. You can index lower-level views, and have more flexibility for using SQL to create the final result, though this will come at the cost of read latency. Or you can index views that are closer to the final representation of the view you need, and you can just issue low-latency point lookups.
The downside of the latter approach is the more you index, the more memory you use and cost you incur. IVMRs let you trade off between flexibility of queries and speed, with the typical best answer still giving you a speedup by multiple orders of magnitude versus running a complex query on a read replica.
The primary tradeoff with IVMRs is they are not designed to support general exploration and ad hoc queries on the raw data; in these cases, a data warehouse would be more appropriate. For queries that have a predictable shape, like those that come from a web service or operational dashboard designed to do things like detect fraud or course correct some supply chain, the results with IVMRs are stellar.
You can see in the table below IVMRs are a solution that finally allows complex queries on fresh data that are also low latency. This allows for more business logic and decisions to react to changes on operational data in real time.
Approaches for Running Complex Queries on Operational Data
To get started with IVMRs, simply attach them to a replication slot in your Postgres or MySQL database, just like a read replica, and use SQL to start defining views. You’ll immediately see dramatic latency reduction for queries on precomputed views that are fast, fresh, and strongly consistent.
You can also subscribe to views or push updates to downstream systems like Kafka or S3. IVMRs don’t use the resources of your primary database to do the computation, and their high levels of efficiency mean you could downsize or completely eliminate your analytical read replicas.
IVMRs in the Real-World
A great example of IVMRs in practice comes from Datalot. They help offload marketing programs from insurance companies and deliver qualified customers directly to the appropriate insurance company or agent. They were struggling to keep their MySQL-powered service online and deliver their various business processes with acceptable levels of latency.
They were able to transition from using eight large read replicas to a much smaller and efficient IVMR, cutting costs by 90%, all while improving the stability of the core database. Once they had access to efficient and fresh views, this ultimately enabled the creation of new services like live dashboards and alerting for customers and internal users alike.
The Missing Element in Your Data Architecture
Differential Dataflow has been the missing element in modern data architecture. Materialize is a cloud operational data store (ODS) that enables you to harness its potential; swapping out read replicas is a great way to see a sample of what it can do.
If your organization struggles with the performance or stability impact of complex read queries on operational databases like Postgres or MySQL, consider using Materialize to implement IVM replicas. You’ll see incredible price-performance by not scaling up inefficient computation, while also giving your system of record some breathing room.
If you’d like to give these a try, you can sign up for a free trial of Materialize here.
